# Java 8 Stream API
# Java 8 介绍
- Java 8 发版于 2014 年,多年过去,目前依旧是最常用的 JDK 版本
- Java 8 在增强代码可读性、简化代码方面,增加了很多功能,比如 Lambda、Stream 流操作、并行流(ParallelStream)、Optional 可空类型、新的日期时间类型等
- Lambda 表达式配合 Stream 流操作为我们日常编码极大的提升了效率
# Lambda 表达式
匿名类内部类虽然没有类名,但还是要给出方法定义
Lambda 表达式的初衷是进一步简化匿名类的语法
在实现上,Lambda 表达式并不是匿名类的语法糖
Lambda 和匿名类的示例
public class ThreadCreator { public static Thread createThreadByAnonymous() { return new Thread(new Runnable() { @Override public void run() { System.out.println("Anonymous thread print"); } }); } public static Thread createThreadByLambda() { return new Thread(() -> { System.out.println("Lambda thread print"); }); } }Lambda 表达式如何匹配类型接口?=> 函数式接口
函数式接口是一种只有单一抽象方法的接口,使用 @FunctionalInterface 来描述,可以隐式地转换成 Lambda 表达式
使用 Lambda 表达式创建函数式接口的示例, 可以让函数成为程序的一等公民,从而像普通数据一样当作参数传递
JDK 的 java.util.function 中提供了许多原生的函数式接口,如 Supplier
@FunctionalInterface public interface Supplier<T> { /** * Gets a result. * * @return a result */ T get(); }使用 Lamda 或方法引用来得到函数式接口的实例
// 使用 Lambda 表达式提供 Supplier 接口实现,返回 OK 字符串 Supplier<String> stringSupplier = () ->"OK"; // 使用方法引用提供 Supplier 接口实现,返回空字符串 Supplier<String> supplier = String::new;方法引用是 Lambda 表达式的另一种表现形式
Lambda 表达式可用方法引用代替的场景:Lambda 表达式的主体仅包含一个表达式,且该表达式仅调用了一个已经存在的方法
方法引用可以是:
- 类 : : 静态方法
- 类 : : new
- 类 : : 实例方法((A, B) -> A.实例方法(B) <=> A 的类 : : 实例方法)
- 任意对象 : : 实例方法
# 创建 Stream
利用 stream 方法将 list 或数组转换为流
Arrays.asList("a1", "a2", "a3").stream().forEach(System.out::println); Arrays.stream(new int[]{1, 2, 3}).forEach(System.out::println);非基本数据类型的数值也可以使用 Arrays.asList 方法转 list 再调 stream
通过 Stream.of 方法直接传入多个元素构成一个流
String[] arr = {"a", "b", "c"}; Stream.of(arr).forEach(System.out::println); Stream.of("a", "b", "c").forEach(System.out::println); Stream.of(1, 2, "a").map(item -> item.getClass().getName()) .forEach(System.out::println);通过 Stream.iterate 方法使用迭代的方式构造一个无限流,然后使用 limit 限制流元素个数
Stream.iterate(2, item -> item * 2).limit(10).forEach(System.out::println); Stream.iterate(BigInteger.ZERO, n -> n.add(BigInteger.TEN)) .limit(10).forEach(System.out::println);通过 Stream.generate 方法从外部传入一个提供元素的 Supplier 来构造无限流,再使用 limit 限制流元素个数
Stream.generate(() -> "test").limit(3).forEach(System.out::println); Stream.generate(Math::random).limit(10).forEach(System.out::println);通过 IntStream 或 DoubleStream 构造基本类型的流
// IntStream 和 DoubleStream IntStream.range(1, 3).forEach(System.out::println); IntStream.range(0, 3).mapToObj(i -> "x").forEach(System.out::println); IntStream.rangeClosed(1, 3).forEach(System.out::println); DoubleStream.of(1.1, 2.2, 3.3).forEach(System.out::println); // 使用 Random 类创建随机流 new Random() .ints(1, 100) // IntStream .limit(10) .forEach(System.out::println); // 注意基本类型流和装箱后的流的区别 Arrays.asList("a", "b", "c").stream() // Stream<String> .mapToInt(String::length) // IntStream .asLongStream() // LongStream .mapToDouble(x -> x / 10.0) // DoubleStream .boxed() // Stream<Double> .mapToLong(x -> 1L) // LongStream .mapToObj(x -> "") // Stream<String> .collect(Collectors.toList());
# 中间操作
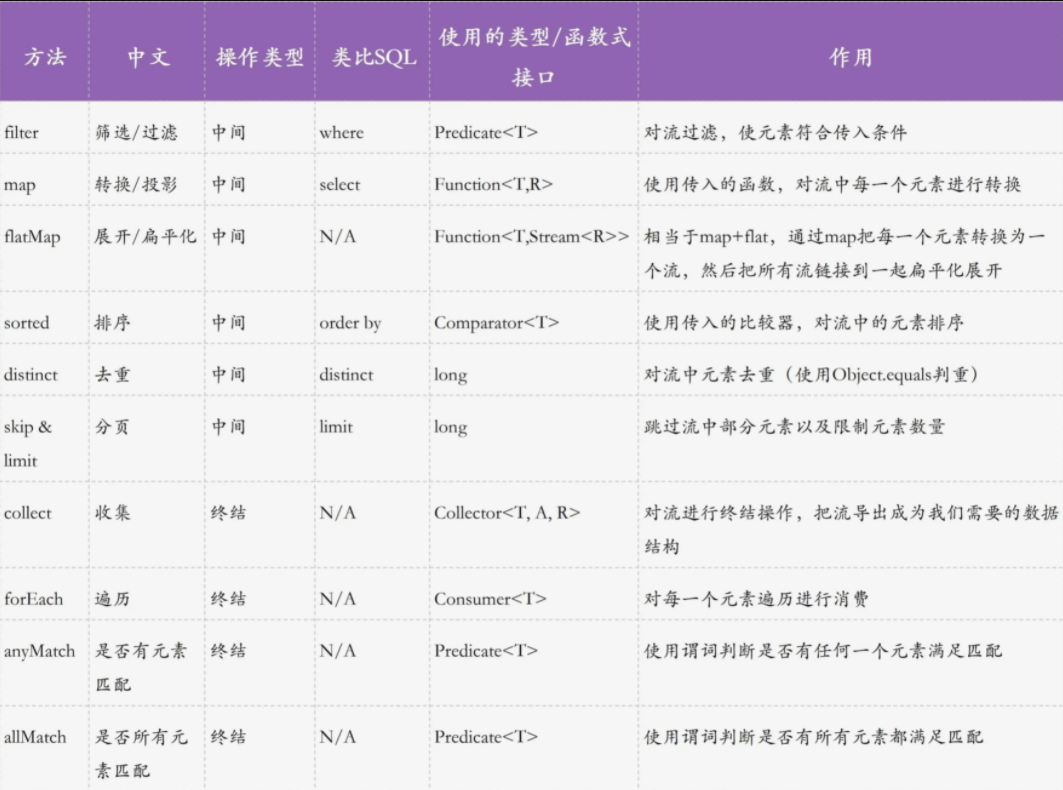
Stream 常用 API:
以下为测试用实体类,代码省略了 getter、settter 和构造方法
订单项
public class OrderItem {
private Long productId;// 商品ID
private String productName;// 商品名称
private Double productPrice;// 商品价格
private Integer productQuantity;// 商品数量
}
订单
public class Order {
private Long id;
private Long customerId;// 顾客ID
private String customerName;// 顾客姓名
private List<OrderItem> orderItemList;// 订单商品明细
private Double totalPrice;// 总价格
private LocalDateTime placedAt;// 下单时间
}
消费者
public class Customer {
private Long id;
private String name;// 顾客姓名
}
# filter
filter 操作用作过滤,类似于 SQL 中的 where 条件,接收一个 Predicate 谓词对象作为参数,返回过滤后的流
可以连续使用 filter 进行多层过滤
// 查找最近半年的金额大于40的订单
orders.stream()
.filter(Objects::nonNull) // 过滤null值
.filter(order -> order.getPlacedAt()
.isAfter(LocalDateTime.now().minusMonths(6))) // 最近半年的订单
.filter(order -> order.getTotalPrice() > 40) // 金额大于40的订单
.forEach(System.out::println);
# map
map 操作用做转换,也叫投影,类似于 SQL 中的 select
// 计算所有订单商品数量
// 1. 通过两次遍历实现
LongAdder longAdder = new LongAdder();
orders.stream().forEach(order ->
order.getOrderItemList().forEach(orderItem -> longAdder.add(orderItem.getProductQuantity())));
System.out.println("longAdder = " + longAdder);
// 2. 使用两次 mapToLong 和 sum 方法实现
long sum = orders.stream().mapToLong(
order -> order.getOrderItemList().stream()
.mapToLong(OrderItem::getProductQuantity)
.sum()
).sum();
# flatMap
flatMap 是扁平化操作,即先用 map 把每个元素替换为一个流,再展开这个流
// 统计所有订单的总价格
// 1. 直接展开订单商品进行价格统计
double sum1 = orders.stream()
.flatMap(order -> order.getOrderItemList().stream())
.mapToDouble(item -> item.getProductQuantity() * item.getProductPrice())
.sum();
// 2. 另一种方式 flatMapToDouble,即 flatMap + mapToDouble,返回 DoubleStream
double sum2 = orders.stream()
.flatMapToDouble(order ->
order.getOrderItemList()
.stream().mapToDouble(item ->
item.getProductQuantity() * item.getProductPrice())
)
.sum();
# sorted
sorted 是排序操作,类似 SQL 中的 order by 子句,接收一个 Comparator 作为参数,可使用 Comparator.comparing 来由大到小排列,加上 reversed 表示倒叙
// 大于 50 的订单,按照订单价格倒序前 5
orders.stream()
.filter(order -> order.getTotalPrice() > 50)
.sorted(Comparator.comparing(Order::getTotalPrice).reversed())
.limit(5)
.forEach(System.out::println);
# skip & limit
skip 用于跳过流中的项,limit 用于限制项的个数
// 按照下单时间排序,查询前 2 个订单的顾客姓名
orders.stream()
.sorted(Comparator.comparing(Order::getPlacedAt))
.map(order -> order.getCustomerName())
.limit(2)
.forEach(System.out::println);
// 按照下单时间排序,查询第 3 和第 4 个订单的顾客姓名
orders.stream()
.sorted(Comparator.comparing(Order::getPlacedAt))
.map(order -> order.getCustomerName())
.skip(2).limit(2)
.forEach(System.out::println);
# distinct
distinct 操作的作用是去重,类似 SQL 中的 distinct
// 去重的下单用户
orders.stream()
.map(Order::getCustomerName)
.distinct()
.forEach(System.out::println);
// 所有购买过的商品
orders.stream()
.flatMap(order -> order.getOrderItemList().stream())
.map(OrderItem::getProductName)
.distinct()
.forEach(System.out::println);
# 终结操作
# forEach
上文中已经多次使用,内部循环流中的所有元素,对每一个元素进行消费
forEachOrder 和 forEach 类似,但能保证消费顺序
# count
返回流中项的个数
# toArray
转换流为数组
# anyMatch
短路操作,有一项匹配就返回 true
// 查询是否存在总价在 100 元以上的订单
boolean b = orders.stream()
.filter(order -> order.getTotalPrice() > 50)
.anyMatch(order -> order.getTotalPrice() > 100);
其他短路操作:
allMatch:全部匹配才返回 true
noneMatch:都不匹配才返回 true
findFirst:返回第一项的 Optional 包装
findAny:返回任意一项的 Optional 包装,串行流一般返回第一个
# reduce
归纳,一边遍历,一边将处理结果保持起来,代入下一次循环
重载方法有三个,截图来自 IDEA 参数提示:

// 一个参数
// 求订单金额总价
Optional<Double> reduce = orders.stream()
.map(Order::getTotalPrice)
.reduce((p, n) -> {
return p + n;
});
// 两个参数
// 可指定一个初始值,初始值类型需要和 p、n 一致
Double reduce2 = orders.stream()
.map(Order::getTotalPrice)
.reduce(0.0, (p, n) -> {
return p + n;
});
三个参数的 reduce 方法:
可以接收一个目标结果类型的初始值,一个串行的处理函数,一个并行的合并函数
// 将所有订单的顾客名字进行拼接
// 第一个参数为目标结果类型,这里设置为空的 StringBuilder
// 第二个参数 BiFunction,参数为上一次的 StringBuilder 和流中的下一项,返回新的 StringBuilder
// 第三个参数 BinaryOperator,参数都是 StringBuilder,返回合并后的 StringBuilder
StringBuilder reduce = orders.stream()
.reduce(new StringBuilder(),
(sb, next) -> {
return sb.append(next.getCustomerName() + ",");
},
(sb1, sb2) -> {
return sb1.append(sb2);
});
其他归纳方法:
max/min 求最大/最小值,接收一个比较器作为参数
对于 LongStream 等基础类型 Stream,则不需要传入比较器参数
# collect
collect 是收集操作,对流进行终结操作,把流导出为我们需要的数据结构
collect 需要接收一个收集器 Collector 对象作为参数,JDK 内置的 Collector 的实现类 Collectors 包含了许多常用的导出方式
collect 常用 API:
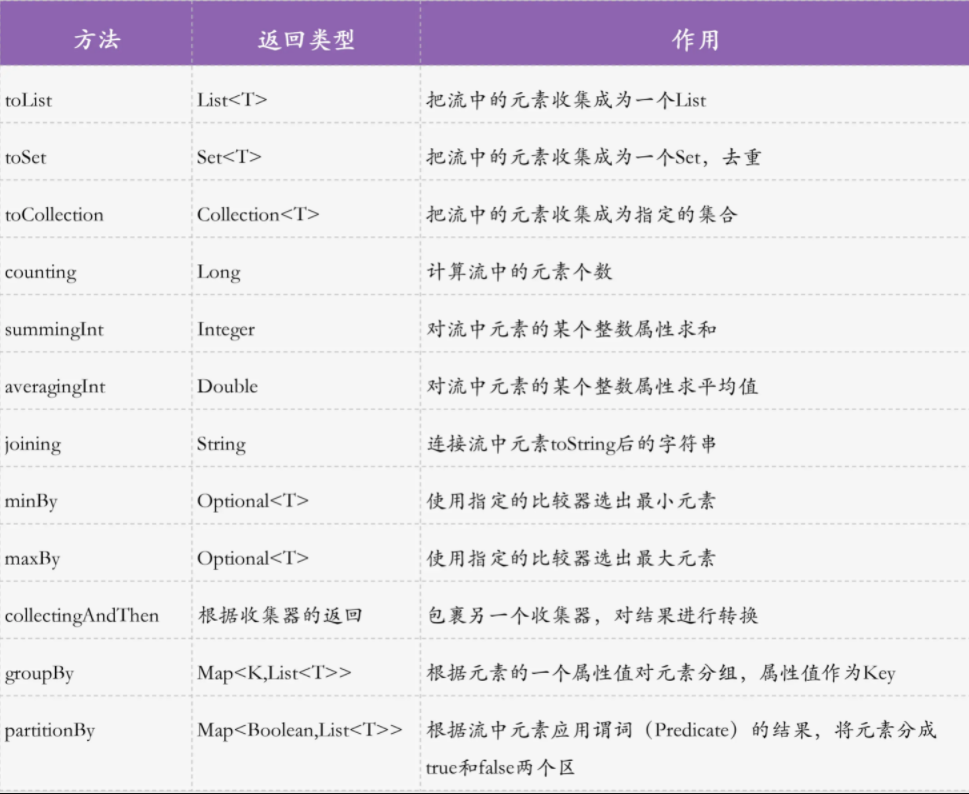
导出流为集合:
- toList 和 toUnmodifiableList
// 转为 List(ArrayList)
orders.stream().collect(Collectors.toList());
// 转为不可修改的 List
orders.collect(Collectors.toUnmodifiableList());
- toSet 和 toUnmodifiableSet
// 转为 Set
orders.stream().collect(Collectors.toSet());
// 转为不可修改的 Set
orders.stream().collect(Collectors.toUnmodifiableSet());
- toCollection 指定集合类型,如 LinkedList
orders.stream().collect(Collectors.toCollection(LinkedList::new));
导出流为 Map:
- toMap,第三个参数可以指定键名重复时选择键值的规则
// 使用 toMap 获取订单 ID + 下单用户名的 Map
orders.stream()
.collect(Collectors.toMap(Order::getId, Order::getCustomerName))
.entrySet().forEach(System.out::println);
//使用 toMap 获取下单用户名 + 最近一次下单时间的 Map
orders.stream()
.collect(Collectors.toMap(Order::getCustomerName, Order::getPlacedAt,
(x, y) -> x.isAfter(y) ? x : y))
.entrySet().forEach(System.out::println);
toUnmodifiableMap:返回一个不可修改的 Map
toConcurrentMap:返回一个线程安全的 Map
分组导出:
在 toMap 中遇到重复的键名,通过指定一个处理函数来选择一个键值保留
大多数情况下,我们需要根据键名分组得到 Map,Collectors.groupingBy 是更好的选择
重载方法有三个,截图来自 IDEA 参数提示:

一个参数,等同于第二个参数为 Collectors.toList,即键值为 List 类型
// 按照下单用户名分组,键值是该顾客对应的订单 List
Map<String, List<Order>> collect = orders.stream()
.collect(Collectors.groupingBy(Order::getCustomerName));
两个参数,第二个参数用于指定键值类型
// 按照下单用户名分组,键值是该顾客对应的订单数量
Map<String, Long> collect = orders.stream()
.collect(Collectors.groupingBy(Order::getCustomerName,
Collectors.counting()));
三个参数,第二个参数用于指定分组结果的 Map 类型,第三个参数用于指定键值类型
// 按照下单用户名分组,键值是该顾客对应的所有商品的总价
Map<String, Double> collect = orders.stream()
.collect(Collectors.groupingBy(Order::getCustomerName,
Collectors.summingDouble(Order::getTotalPrice)));
// 指定分组结果的 Map 为 TreeMap 类型
Map<String, Double> collect = orders.stream()
.collect(Collectors.groupingBy(Order::getCustomerName,
TreeMap::new,
Collectors.summingDouble(Order::getTotalPrice)));
分区导出:
分区使用 Collectors.partitioningBy,就是将数据按照 TRUE 或者 FALSE 进行分组
// 按照是否有下单记录进行分区
customers.stream()
.collect(Collectors.partitioningBy(customer -> orders
.stream()
.mapToLong(Order::getCustomerId)
.anyMatch(id -> id == customer.getId())
));
// 等价于
customers.stream()
.collect(Collectors.partitioningBy(customer -> orders
.stream()
.filter(order -> order.getCustomerId() == customer.getId())
.findAny()
.isPresent()
));
类中间操作:
Collectors 还提供了类似于中间操作的 API,方便在收集时使用,如 counting、summingDouble、maxBy 等
Collectors.maxBy
// 获取下单量最多的商品,三种方式
// 使用收集器 maxBy
Map.Entry<String, Integer> e1 = orders.stream()
.flatMap(order -> order.getOrderItemList().stream())
.collect(Collectors.groupingBy(OrderItem::getProductName,
Collectors.summingInt(OrderItem::getProductQuantity)))
.entrySet()
.stream()
.collect(Collectors.maxBy(Map.Entry.<String, Integer>comparingByValue()))
.get();
// 使用中间操作 max
Map.Entry<String, Integer> e2 = orders.stream()
.flatMap(order -> order.getOrderItemList().stream())
.collect(Collectors.groupingBy(OrderItem::getProductName,
Collectors.summingInt(OrderItem::getProductQuantity)))
.entrySet()
.stream()
.max(Map.Entry.<String, Integer>comparingByValue())
.get();
// 由大到小排序,再 findFirst
Map.Entry<String, Integer> e3 = orders.stream()
.flatMap(order -> order.getOrderItemList().stream())
.collect(Collectors.groupingBy(OrderItem::getProductName,
Collectors.summingInt(OrderItem::getProductQuantity)))
.entrySet()
.stream()
.sorted(Map.Entry.<String, Integer>comparingByValue().reversed())
.findFirst()
.get();
// 注:
// Map.Entry.<String, Integer>comparingByValue().reversed()
// 可以与下面语句等价
// Comparator.comparing(Map.Entry<String, Integer>::getValue).reversed()
Collectors.joining
// 下单用户名去重后拼接
String collect = orders.stream()
.map(Order::getCustomerName)
.distinct()
.collect(Collectors.joining(","));
// .collect(Collectors.joining(",", "[", "]")); // 可指定前缀和后缀