# Kafka 使用和集群
# Kafka 简介
# 基本介绍
Kafka 是一种高吞吐量、持久性、分布式的、支持发布订阅的消息队列系统
Kafka 最初由 LinkedIn(领英)公司发布,其前身是一个 log commit 工具,使用 Scala 语言编写,于 2010 年开源到 Apache,成为 Apache 的顶级项目
目前 Apahe Kafka 被广泛运用到事件驱动架构、流式数据处理、日志收集分析等领域
Kafka 的特性:
- 高吞吐量:每秒可以处理几十万条消息
- 可扩展性:集群支持热扩展
- 可靠性:消息被持久化到本地磁盘,并且支持数据副本机制防止数据丢失
- 容错性:允许集群中节点失败,支持自动的故障转移
- 高并发:支持数千个客户端同时读写
# 基础架构
# 设计思想
Producer
消息生产者,向 Broker 发送消息
Consumer
消息消费者,从 Broker 拉取消息
Consumer Group
消费者组成的组,一个消息分区不能被同一组的多个消费者消费,但一个消费者可以消费多个分区
Broker
经纪,负责管理和投递消息,多个 Broker 组成 Kafka 集群
Topic
消息主题,一个主题可以有多个分区,可以理解为多个队列的集合,生产者和消费者面向的是主题
Partition
消息分区,一个分区可以理解为一个队列,一个分区内消息是有序。一个主题的所有分区按照一定规则分散到多个 Broker 节点上。每个 Broker 节点拥有该主题的部分分区或全部分区
Replication
分区副本,为了保证可靠性,主题的每个分区都会有若干副本,分布在一些 Broker 上,在节点故障时,可以从副本中恢复数据继续提供服务。副本中会有一个是 Leader,其他副本是 Follower
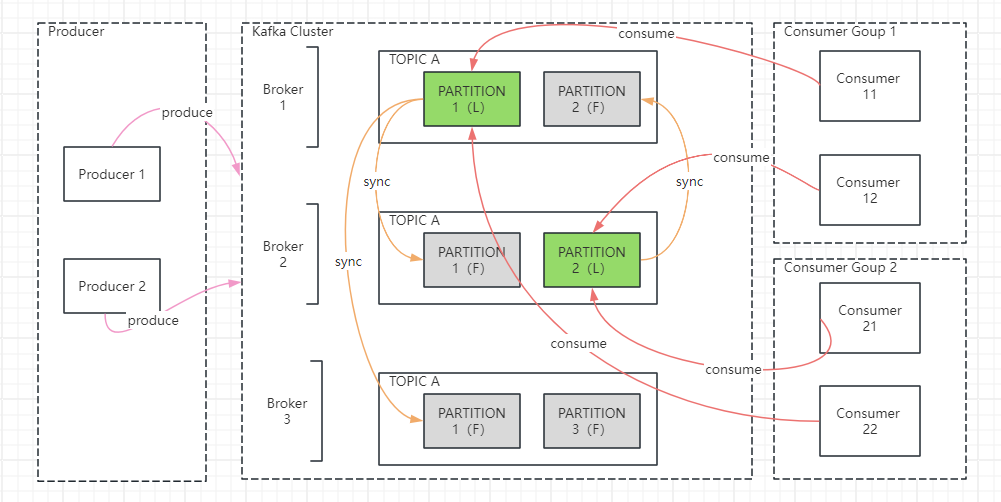
从上图中可见
生产者向 Kafka 集群发送消息
主题 A 的分区 1 在三台 Broker 上都有,Broker 1 上的是 Leader,其他副本未知
主题 A 的分区 2 在 Broker 1 和 2 有,Broker 2 上的是 Leader,其他副本未知
主题 A 的分区 3 在 Broker 3 有,Leader 未知,其他副本未知
分区的 Leader 副本负责向 Follower 副本同步数据
一个分区可以被多个消费者组的消费者消费,但每组只能出一个消费者
生产者和消费者面向的是主题分区的 Leader 副本
# 主要特性
AR/ISR/OSR
AR:一个分区所有被分配的副本
ISR:一个分区的副本中和 Leader 保持同步的副本集,包括 Leader
OSR:因为节点存在问题,导致同步落后的副本会被踢出 ISR,进入 OSR,当后期追赶上后会重新移入 ISR
消费状态
Kafka 中并不关系消息是否被消费,只维护消费到的 offset。调整 offset 可能导致消息重复消费
消息持久化
Kafka 会把消息持久化到本地文件系统中,并且长久保留,其过期时间以及其他许多细节是可配置的
批量发送
Kafka 支持以消息集合为单位进行批量发送,以提高推送效率
消息压缩
Kafka 支持对消息集合进行压缩,生产者进行压缩之后,消费者需进行解压。Kafka 在消息头部添加了一个描述压缩属性的字节,用来标识消息的压缩采用的编码
消息可靠性
生产者发送消息时,支持失败重试和等待确认,可以保证生产者消息到达 Broker。生产者也支持开启幂等,可以保证 exactly-once 语义。消费者需要在消费成功后再提交 offset,以便出现异常时,可以重新消费,但需要注意处理业务时的幂等性
重平衡机制
当消费者上下线、分区重新调整数量时,会对分区和消费者关系进行重新分配。一般有 Range、RoundRobin 等策略
# 消息模式
消息从生产者到消费者的大致流程
1. 生产者找到分区的 Leader 副本
2. 发送消息,Leader 副本写入 log
3. Follower 副本 pull 消息,同步完成后向 Leader 发送 ACK
4. Leader 收到满足数量要求的 Follower 后,向生产者回复 ACK
5. 消费者 pull 消息,并处理消息
6. 消费者提交 offset
点对点:只有一个消费者组消费该主题,每条消息只发送给一个消费者
发布订阅:多个消费者组的消费者消费该主题,每条消息都会发送到所有消费者组
# Kafka 使用
# 安装 Kafka
低版本 Kafka 依赖 zookeeper 做状态管理、元数据管理,所以安装低版本的 Kafka 需要先安装 zookeeper
在 Kafka 3.x 版本中,Kafka 基于 KRaft 替代了 zookeeper,不再依赖 zookper 实现相关功能
使用 docker 安装单节点的 Kafka 3.2,基于 bitnami/kafka:3.2 镜像
docker run --name kafka \
--restart=unless-stopped \
--network=docker_net \
--hostname=kafka-0 \
-p 9092:9092 \
-p 9094:9094 \
-v /docker/kafka/data:/bitnami/kafka \
-e KAFKA_CFG_NODE_ID=0 \
-e KAFKA_CFG_PROCESS_ROLES=controller,broker \
-e KAFKA_CFG_LISTENERS=INTERNAL://:9092,CONTROLLER://:9093,EXTERNAL://0.0.0.0:9094 \
-e KAFKA_CFG_ADVERTISED_LISTENERS=INTERNAL://kafka-0:9092,EXTERNAL://172.19.85.141:9094 \
-e KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,EXTERNAL:PLAINTEXT,INTERNAL:PLAINTEXT \
-e KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=0@kafka-0:9093 \
-e KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER \
-d bitnami/kafka:3.2
指定 network 和 hostname
使用 -v 将容器内路径 /bitnami/kafka 持久化到宿主环境
使用 -e 配置变量,Kafka 容器的配置一般都以 KAFKA_ 开头,其中以 KAFKA_CFG 开头的变量会被映射到 Kafka 的配置项,如 KAFKA_CFG_AUTO_CREATE_TOPICS_ENABLE 表示 auto.create.topics.enable
# 配置项和常用命令
Kafka 在 KRaft 模式下,有三大配置文件
broker.properties 当节点作为 broker 角色运行时生效
controller.properties 当节点作为 controller 角色运行时生效
server.properties 当节点同时作为 broker、controller 角色运行时生效
常见配置项
KAFKA_KRAFT_CLUSTER_I:集群 ID
KAFKA_CFG_NODE_ID:节点 ID,同一集群内节点 ID 不允许重复
KAFKA_CFG_PROCESS_ROLES:节点的角色,可指定为 broker 或 controller,或者二者都有
KAFKA_CFG_LISTENERS:节点监听器,通常不同的角色会监听不同的端口,格式是 {LISTENER_NAME}://{hostname}:{port}
KAFKA_CFG_ADVERTISED_LISTENERS:listeners 选项配置了 server 的端口监听方式。此配置项用于宣告对外公开的访问方式,格式和 listeners 一致
KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP:监听器对应的安全协议
KAFKA_CFG_CONTROLLER_QUORUM_VOTERS:集群内所有的 controller 节点,格式是 {nodeId}@{hostname}:{port}
KAFKA_CFG_CONTROLLER_LISTENER_NAMES:controller 监听器名称
KAFKA_CFG_INTER_BROKER_LISTENER_NAME:其它 broker 节点与本节点通信的监听器名称
注意:
KAFKA_CFG_ADVERTISED_LISTENERS 用于宣告客户端的访问方式,如 EXTERNAL://172.19.85.141:9094,表示外部客户端访问的 IP 和端口。可以配置多种方式来区分内网和外网流量
常用命令
Kafka 安装包中内置了许多 sh 文件,可以帮组管理 Kafka 的主题、分区等
在 docker 安装的 Kafka 容器中,使用这些命令文件需要使用 docker exec 命令来运行
kafka-topics.sh:查看、创建、删除、调整主题及分区
kafka-console-producer.sh:用于测试的控制台生产者
kafka-console-consumer.sh:用于测试的控制台消费者
kafka-consumer-groups.sh:查看消费者组
kafka-run-class.sh:执行指定 class,是其他命令的基础
# 生产者 API
引入 maven 包
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.2.3</version>
</dependency>
异步发送
Properties props = new Properties();
props.put("bootstrap.servers", "172.19.85.141:9094");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 20; i++) {
String key = "KEY_" + i;
String msg = "MSG_" + i;
producer.send(new ProducerRecord<>("my-topic", key, msg));
}
producer.close();
send 方法有重载方法可以指定分区
同步发送
Properties props = new Properties();
props.put("bootstrap.servers", "172.19.85.141:9094");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 20; i++) {
String key = "KEY_" + i;
String msg = "MSG_" + i;
Future<RecordMetadata> future = producer.send(new ProducerRecord<>("my-topic", key, msg));
try {
RecordMetadata recordMetadata = future.get();
} catch (InterruptedException | ExecutionException e) {
throw new RuntimeException(e);
}
}
producer.close();
批量发送
Properties props = new Properties();
props.put("bootstrap.servers", "172.19.85.141:9094");
// 一批最大大小
props.put("batch.size", 16384);
// 一批最大等待时间
props.put("linger.ms", 1000);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 20; i++) {
String key = "KEY_" + i;
String msg = "MSG_" + i;
producer.send(new ProducerRecord<>("my-topic", key, msg));
try {
Thread.sleep(100);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
producer.close();
可靠发送
Properties props = new Properties();
props.put("bootstrap.servers", "172.19.85.141:9094");
props.put("batch.size", 16384);
props.put("linger.ms", 1000);
// 等待服务端确认落盘
// 0 =不等待,1 = 等待 leader 落盘(默认),-1/all = 等待所有副本的落盘
props.put("acks", "all");
// 发送失败的重试
props.put("retries", 5);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 20; i++) {
String key = "KEY_" + i;
String msg = "MSG_" + i;
producer.send(new ProducerRecord<>("my-topic", key, msg));
try {
Thread.sleep(100);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
producer.close();
# 消费者 API
maven 引入同样的 kafka-clients 包
消费者与消费位置
Kafka 中有个系统主题,__consumer_offsets,用来保存消费者消费到哪个主题、哪个分区、哪个位置。消费者的提交动作就是在改变消费位置
消费自动提交
Properties props = new Properties();
props.setProperty("bootstrap.servers", "172.19.85.141:9094");
props.setProperty("group.id", "test");
// 开启自动提交
props.setProperty("enable.auto.commit", "true");
props.setProperty("auto.commit.interval.ms", "1000");
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("my-topic"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
消费手动批量提交
Properties props = new Properties();
props.setProperty("bootstrap.servers", "172.19.85.141:9094");
props.setProperty("group.id", "test");
// 关闭自动提交
props.setProperty("enable.auto.commit", "false");
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("my-topic"));
final int minBatchSize = 200;
List<ConsumerRecord<String, String>> buffer = new ArrayList<>();
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
buffer.add(record);
}
if (buffer.size() >= minBatchSize) {
// 模拟处理动作
// insertIntoDb(buffer);
// 批量提交
consumer.commitSync();
buffer.clear();
}
}
消费手动逐条提交
Properties props = new Properties();
props.setProperty("bootstrap.servers", "172.19.85.141:9094");
props.setProperty("group.id", "test");
props.setProperty("enable.auto.commit", "false");
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("my-topic"));
final int minBatchSize = 200;
List<ConsumerRecord<String, String>> buffer = new ArrayList<>();
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(Long.MAX_VALUE));
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);
for (ConsumerRecord<String, String> record : partitionRecords) {
System.out.println(record.offset() + ": " + record.value());
}
// 获取 offset
long lastOffset = partitionRecords.get(partitionRecords.size() - 1).offset();
// 更新指定分区和消费位置
consumer.commitSync(Collections.singletonMap(partition, new OffsetAndMetadata(lastOffset + 1)));
}
}
消费指定分区
Properties props = new Properties();
props.setProperty("bootstrap.servers", "172.19.85.141:9094");
props.setProperty("group.id", "test");
props.setProperty("enable.auto.commit", "true");
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 指定分区消费
TopicPartition topicPartition0 = new TopicPartition("my-topic", 0);
TopicPartition topicPartition1 = new TopicPartition("my-topic", 1);
consumer.assign(Arrays.asList(topicPartition0, topicPartition1));
List<ConsumerRecord<String, String>> buffer = new ArrayList<>();
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
消费指定位置
Properties props = new Properties();
props.setProperty("bootstrap.servers", "172.19.85.141:9094");
props.setProperty("group.id", "test");
props.setProperty("enable.auto.commit", "true");
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
TopicPartition topicPartition0 = new TopicPartition("my-topic", 0);
// 指定分区和消费位置
consumer.assign(Arrays.asList(topicPartition0));
consumer.seek(topicPartition0, 100);
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
可以使用 seek 方法,对某个分区指定 offset
也可通过配置 auto.offset.reset 来影响 offset 位置的选择,可配置为 lastest/earliest
需要注意的是,如果当前 Group ID 在 Broker 存在消费过的记录,就会接上次 offset 继续消费
如果是新的 Group ID,earliest 表示从头消费,lastest 表示从最新位置,默认为 lastest
# 消息传递语义
至少一次 at-least-once
生产者:acks 为 all,retries > 0
消费者:先处理,再提交 offset
最多一次 at-most-once
生产者:acks 为 0 或 1,retries = 0
消费者:先提交 offset,再处理
精确一次 exactly-once
生产者:enable.idempotence 为 true,acks 为 all,retries 为 Integer.MAX_VALUE
消费者:先处理,处理逻辑做幂等,再提交 offset
# 与 SpringBoot 集成
引入 maven 包
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.2.6.RELEASE</version>
</dependency>
基本配置
spring:
kafka:
bootstrap-servers: 1
consumer:
group-id: test
支持配置其他 producer、consumer、listener 等属性,如 consumer 的 enable-auto-commit、producer 的 retries、acks 等
发送消息
@Autowired
private KafkaTemplate<Object, Object> kafkaTemplate;
public void sendHello() {
kafkaTemplate.send("my-topic", "Hello");
}
注入 kafkaTemplate 提供了发送消息的方法,是异步方法,可以通过返回的 ListenableFuture 来同步处理
接收消息
@KafkaListener(id = "hello-listener1", topics = "my-topic", groupId = "test")
public void listenHello1(String msg) {
log.info("msg value: {}", msg);
}
@KafkaListener 还支持指定分区、指定 offset、指定并发度等
@KafkaListener(id = "hello-listener2",
groupId = "test",
topicPartitions = {
@TopicPartition(
topic = "my-topic",
partitions = {"0", "1"},
partitionOffsets = {
@PartitionOffset(partition = "0", initialOffset = "100")
}
)
},
concurrency = "6")
public void listenHello2(String msg) {
log.info("msg value: {}", msg);
}
手动 ACK
配置 Kafka 关闭自动提交,ack-mode 设置为 manual
spring:
kafka:
bootstrap-servers: 1
consumer:
group-id: test
enable-auto-commit: false
listener:
ack-mode: manual
@KafkaListener(id = "manual-listener", topics = "my-topic")
public void listenManualAck(String msg, Acknowledgment ack) {
log.info("msg value: {}", msg);
// 处理消息的逻辑
// ...
// 手动提交偏移量
ack.acknowledge();
}
创建 topic
通过注册 NewTopic 的 Bean 来自动创建 topic
@Configuration
public class KafkaAutoConfig {
@Bean
public KafkaAdmin kafkaAdmin(KafkaProperties properties){
KafkaAdmin admin = new KafkaAdmin(properties.buildAdminProperties());
admin.setFatalIfBrokerNotAvailable(true);
return admin;
}
@Bean
public NewTopic kafkaMyTopic() {
return new NewTopic("my-topic", 1, (short) 1);
}
}
使用 KafkaAdmin API 创建 topic
@Component
public class KafkaTopicCreator {
@Autowired
private KafkaAdmin kafkaAdmin;
public void createTopic(String topicName, int numPartitions, short replicationFactor) {
AdminClient adminClient = AdminClient.create(kafkaAdmin.getConfig());
NewTopic newTopic = new NewTopic(topicName, numPartitions, replicationFactor);
adminClient.createTopics(Collections.singleton(newTopic));
adminClient.close();
}
}
消息转发
@KafkaListener(id = "hello-listener3", topics = "my-topic")
@SendTo("my-topic2")
public String listenHello3(String msg) {
log.info("msg value: {}", msg);
return msg + "OK!";
}
当一个消息需要做多重加工,使用 @SendTo 指定下一处理环节的 topic
消费重试
方式一:配置 CommonErrorHandler 来重试消息
@Bean
public CommonErrorHandler errorHandler() {
// spring-kafka 3.1 版本中默认是 FixedBackOff(0L, 9)
BackOff fixedBackOff = new FixedBackOff(3000L, 5);
DefaultErrorHandler errorHandler = new DefaultErrorHandler((consumerRecord, exception) -> {
// 重试都失败时的兜底操作
}, fixedBackOff);
// 设置需要重试异常
errorHandler.addRetryableExceptions(SocketTimeoutException.class);
errorHandler.addNotRetryableExceptions(NullPointerException.class);
return errorHandler;
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, Object> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, Object> factory = new ConcurrentKafkaListenerContainerFactory<>();
// 设置 ACK Mode,RECORD 表示手动调用 Acknowledgment.acknowledge() 后立即提交
factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.RECORD);
// 设置 errorHandler
factory.setCommonErrorHandler(errorHandler());
return factory;
}
通过配置 ConcurrentKafkaListenerContainerFactory 的 Bean,设置 CommonErrorHandler,在消费失败时根据 CommonErrorHandler 配置的重试次数、间隔和异常来进行处理,一般配合 AckMode.RECORD 或手动提交来使用
CommonErrorHandler 会阻塞 Listener 的持续监听处理,等待当前消费重试完成
在 spring-kafka 3.x 版本中,DefaultErrorHandler 取代了 SeekToCurrentErrorHandler 和 RecoveringBatchErrorHandler
方式二:使用 RetryableTopic + DLT 实现重试
@KafkaListener(id = "retry-listener", topics = "my-topic")
@RetryableTopic(
backoff = @Backoff(value = 3000L),
attempts = "5",
autoCreateTopics = "true",
include = SocketTimeoutException.class,
exclude = NullPointerException.class)
public void listenRetry(String msg) {
log.info("msg value: {}", msg);
}
@DltHandler
public void processMessage(String msg) {
// DLT 处理
}
backoff:该属性指定在重试失败的消息时要使用的退避策略
attempts:该属性指定在放弃之前消息应该重试的最大次数
autoCreateTopics:如果 retry topic 和 DLT(死信 Topic)不存在,该属性指定是否自动创建它们
include:指定需要触发重试的异常
exclude:指定不需要触发重试的异常
当 main topic 消费失败时,会将消息转发到 retry topic,有专门的监听线程负责消费重试,若 retry topic 最终也处理失败,那么将转发到死信队列
@DltHandler 标注的方法将用于处理该 class 下所有带 @RetryableTopic 的监听器
这一过程不会影响 main topic 线程的 commit,是一种异步的处理手段
# Kafka 集群
在 Kafka 2.8 版本中 Kafka 使用 KRaft 实现了元数据管理和服务间共识,在 3.x 版本中此功能达到稳定
KRaft 架构中,每个 Kafka 节点具有角色之分,可以是 Controller,可以是 Broker,也可以二者皆有。Controller 节点组成的集群,基于 Raft 算法,达到共识选主的作用。Kafka 节点会从 Controller Leader 拉取集群的元数据信息
下面是使用 Docker 运行 Kafka 集群的命令。该集群有 3 个节点,每个节点都是 Controller 和 Broker
docker run --name kafka-cluster-0 \
--restart=unless-stopped \
--network=docker_net \
--hostname=kafka-cluster-0 \
-p 9095:9095 \
-v /docker/kafka-cluster/0/data:/bitnami/kafka \
-e KAFKA_CFG_NODE_ID=0 \
-e KAFKA_CFG_PROCESS_ROLES=controller,broker \
-e KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=0@kafka-cluster-0:9093,1@kafka-cluster-1:9093,2@kafka-cluster-2:9093 \
-e KAFKA_KRAFT_CLUSTER_ID=abcdefghijklmnopqrstuv \
-e KAFKA_CFG_LISTENERS=INTERNAL://:9092,CONTROLLER://:9093,EXTERNAL://0.0.0.0:9095 \
-e KAFKA_CFG_ADVERTISED_LISTENERS=INTERNAL://kafka-cluster-0:9092,EXTERNAL://172.19.85.141:9095 \
-e KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,EXTERNAL:PLAINTEXT,INTERNAL:PLAINTEXT \
-e KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER \
-e KAFKA_CFG_INTER_BROKER_LISTENER_NAME=INTERNAL \
-e KAFKA_CFG_OFFSETS_TOPIC_REPLICATION_FACTOR=3 \
-e KAFKA_CFG_TRANSACTION_STATE_LOG_REPLICATION_FACTOR=3 \
-e KAFKA_CFG_TRANSACTION_STATE_LOG_MIN_ISR=2 \
-d bitnami/kafka:3.2;
docker run --name kafka-cluster-1 \
--restart=unless-stopped \
--network=docker_net \
--hostname=kafka-cluster-1 \
-p 9096:9096 \
-v /docker/kafka-cluster/1/data:/bitnami/kafka \
-e KAFKA_CFG_NODE_ID=1 \
-e KAFKA_CFG_PROCESS_ROLES=controller,broker \
-e KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=0@kafka-cluster-0:9093,1@kafka-cluster-1:9093,2@kafka-cluster-2:9093 \
-e KAFKA_KRAFT_CLUSTER_ID=abcdefghijklmnopqrstuv \
-e KAFKA_CFG_LISTENERS=INTERNAL://:9092,CONTROLLER://:9093,EXTERNAL://0.0.0.0:9096 \
-e KAFKA_CFG_ADVERTISED_LISTENERS=INTERNAL://kafka-cluster-1:9092,EXTERNAL://172.19.85.141:9096 \
-e KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,EXTERNAL:PLAINTEXT,INTERNAL:PLAINTEXT \
-e KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER \
-e KAFKA_CFG_INTER_BROKER_LISTENER_NAME=INTERNAL \
-e KAFKA_CFG_OFFSETS_TOPIC_REPLICATION_FACTOR=3 \
-e KAFKA_CFG_TRANSACTION_STATE_LOG_REPLICATION_FACTOR=3 \
-e KAFKA_CFG_TRANSACTION_STATE_LOG_MIN_ISR=2 \
-d bitnami/kafka:3.2;
docker run --name kafka-cluster-2 \
--restart=unless-stopped \
--network=docker_net \
--hostname=kafka-cluster-2 \
-p 9097:9097 \
-v /docker/kafka-cluster/2/data:/bitnami/kafka \
-e KAFKA_CFG_NODE_ID=2 \
-e KAFKA_CFG_PROCESS_ROLES=controller,broker \
-e KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=0@kafka-cluster-0:9093,1@kafka-cluster-1:9093,2@kafka-cluster-2:9093 \
-e KAFKA_KRAFT_CLUSTER_ID=abcdefghijklmnopqrstuv \
-e KAFKA_CFG_LISTENERS=INTERNAL://:9092,CONTROLLER://:9093,EXTERNAL://0.0.0.0:9097 \
-e KAFKA_CFG_ADVERTISED_LISTENERS=INTERNAL://kafka-cluster-2:9092,EXTERNAL://172.19.85.141:9097 \
-e KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,EXTERNAL:PLAINTEXT,INTERNAL:PLAINTEXT \
-e KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER \
-e KAFKA_CFG_INTER_BROKER_LISTENER_NAME=INTERNAL \
-e KAFKA_CFG_OFFSETS_TOPIC_REPLICATION_FACTOR=3 \
-e KAFKA_CFG_TRANSACTION_STATE_LOG_REPLICATION_FACTOR=3 \
-e KAFKA_CFG_TRANSACTION_STATE_LOG_MIN_ISR=2 \
-d bitnami/kafka:3.2;
容器指定到一个 docker 网络中,分别配置了 hostname,便于内网互相访问
其他参数含义:
KAFKA_CFG_NODE_ID:设置不同的 NODE_ID 标识集群节点
KAFKA_KRAFT_CLUSTER_ID:同一个集群要设置相同的 CLUSTER_ID
KAFKA_CFG_CONTROLLER_QUORUM_VOTERS:用于指定集群中 Controller 节点有哪些
KAFKA_CFG_ADVERTISED_LISTENERS:配置用于外部 Client 访问的 IP 和端口
KAFKA_CFG_OFFSETS_TOPIC_REPLICATION_FACTOR:主题 __consumer_offsets 的复制因子
KAFKA_CFG_TRANSACTION_STATE_LOG_REPLICATION_FACTOR:事务状态日志的复制因子
KAFKA_CFG_TRANSACTION_STATE_LOG_MIN_ISR:提交事务需要达到的事务状态日志的最小副本数