# MySQL 搭建主从复制
# 主从复制概念
主从复制是 MySQL 本身提供一种多处自动备份数据的功能
主从复制可以提高数据的安全性,更是利用读写分离提升负载性能的基石
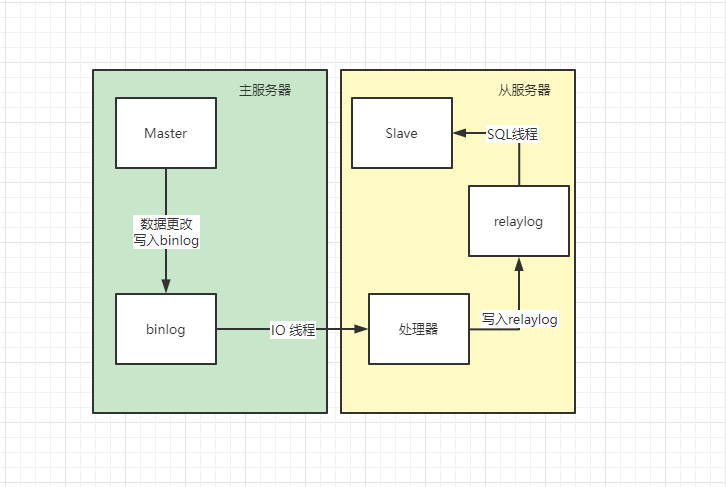
主从复制的基本流程
主库的数据更改记录到 binlog 文件中,开启一个 IO 线程,维持一个长连接,发送日志到从库
从库 IO 线程接收文件内容并解析到 relaylog 中,由 SQL 线程执行数据重放
# 搭建主从复制
使用 docker 启动多个 MySQL 容器进行模拟
# 使用 docker 安装拉取 MySQL 镜像 docker pull mysql:8.0.27 # 创建一个 docker 网络 docker network create mysql_cluster # 启动两个 MySQL 容器 # mysql_1 docker run \ --name mysql_1 \ --network mysql_cluster \ --ip 172.17.0.3 \ -p 3307:3306 \ -e MYSQL_ROOT_PASSWORD=root1 \ -d mysql:8.0.27 # mysql_2 docker run \ --name mysql_2 \ --network mysql_cluster \ --ip 172.17.0.2 \ -p 3308:3306 \ -e MYSQL_ROOT_PASSWORD=root2 \ -d mysql:8.0.27 # 查询容器 IP docker inspect mysql_1 | grep -A20 IPAddress # 进入两个容器 docker exec -it mysql_1 bash docker exec -it mysql_2 bash # 在容器内安装可能用到的其他工具包,如 vim 等进入容器,测试登录 MySQL
修改 MySQL 配置文件
vim /etc/mysql/my.cnf常见配置如下
主库
# 开启二进制日志 log-bin=mysql-bin # 设置唯一的 server id server-id=1 # 需要同步的数据库,不设置表示同步所有 # binlog-do-db=test # 不同步的数据库 # binlog-ignore-db=mysql从库
server-id=2配置完毕后重启
docker restart mysql_1主库增加账户用于复制
# 创建用户 CREATE USER 'repl'@'%' IDENTIFIED BY 'repl'; # 分配权限 GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%'; FLUSH PRIVILEGES;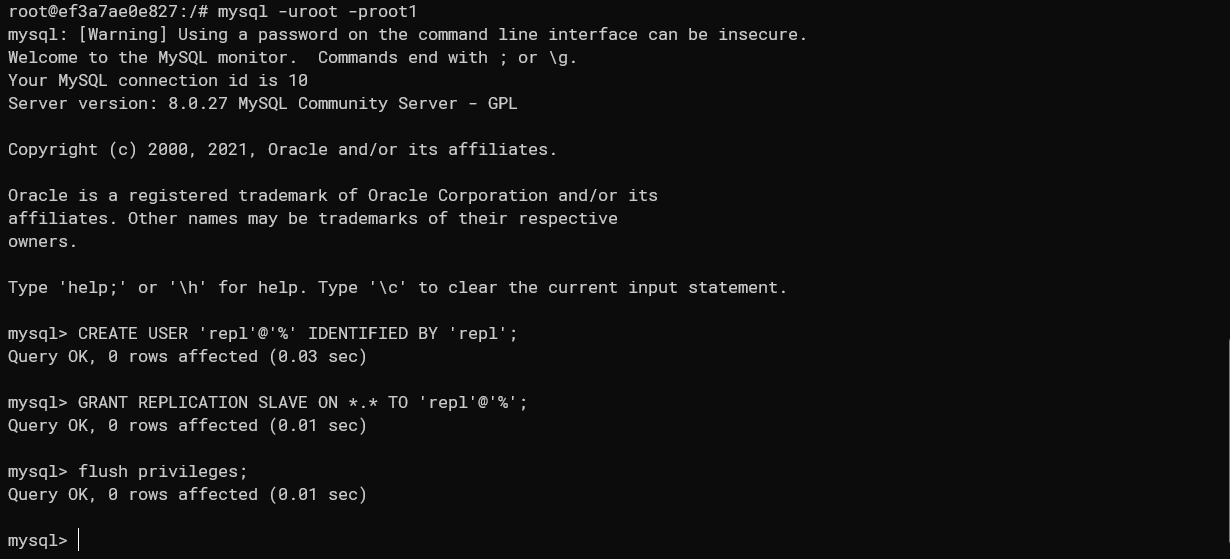
查询主库状态
show master status;
记下文件名和 Position
从库开启复制
设置 master
CHANGE MASTER TO MASTER_HOST='mysql_1', MASTER_USER='repl', MASTER_PASSWORD='repl', MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=156; # MASTER_LOG_POS 设置到 Position开启复制
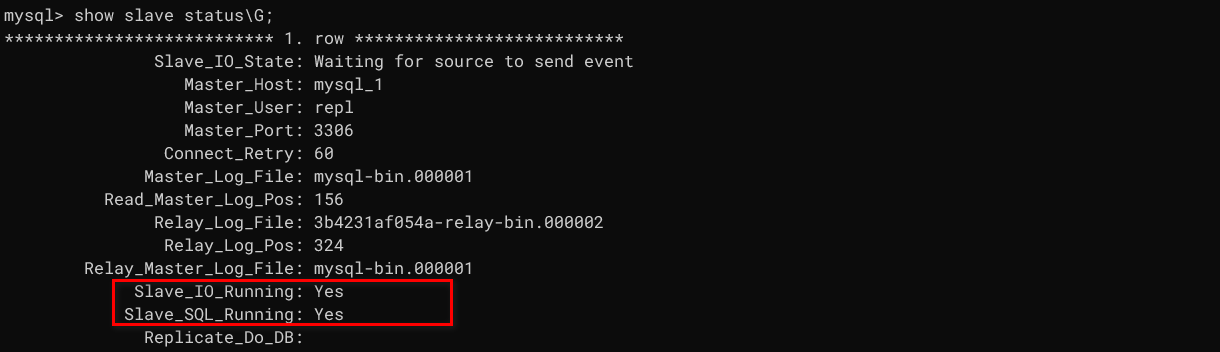
start slave;查询 slave 状态
show slave status\G;出现两个 YES 代表主从复制启动成功
主库添加数据测试

从库查询

# BINLOG 格式
binlog 是归档日志,用于记录 MySQL 数据变更履历
binlog 有三种格式,可以通过配置文件 my.cnf 配置
binlog_format=statement默认格式是 statement,里面记录的就是 SQL 语句的原文,在主从复制的架构中,不建议使用 statement 格式,因为可能导致主从不一致,例如一个带 limit 的 delete 语句
delete from t where a >= 1 and b <= 2 limit 1;如果 a,b 都是索引,在主从库上执行时选择的索引可能不一致,导致 limit 的结果不同,删除了不同的数据,造成主从不一致
当配置成 row 格式的时候,binlog 会记录每一行操作的细节,如果批量修改数据,记录的不是批量修改的SQL 语句事件,而是每条记录被更改的 SQL 语句,row 模式可以保证主从同步的一致性,但是会占用更大空间,耗费 IO 资源,影响执行速度
由于 row 格式日志数据量很大,可以配置 binlog_row_image
binlog_row_image=fullfull 模式会记录所有的列,minimal 模式只会记录被修改的列,noblob模式在没有对 text、blob 列进行修改时不会记录 text、blob 列
mixed 格式是一个折中方案,MySQL 会自动判断 SQL 是否会引起主从不一致,从而调整日志的生成策略
# GTID 复制
GTID 意思是全局事务 ID,在 MySQL 5.6 之后完善支持
每个事务在执行前生成唯一的事务 ID,记录到 binlog 中,从库会从 relaylog 获取 GTID 结合自身 binlog 来判断事务是否执行,如果已经执行就忽略
GTID 模式的优缺点
优点:不需要指定日志文件名称和位置,减少手工干预
缺点:不支持非事务引擎
开启 GTID 模式复制
gtid_mode = on # 强制限制事务安全的语句才能被执行 enforce_gtid_consistency = 1 # 从库同步主库数据时写入 binlog log_slave_updates = onMySQL5.7 中,不再要求开启 log_slave_updates,官方改为使用 gtid_executed 表记录同步复制信息
但如果是级联主从模式,如 A -> B -> C,那么中间节点 B 需要开启 log_slave_updates
在从库上设置 master
CHANGE MASTER TO MASTER_HOST='mysql_1', MASTER_USER='repl', MASTER_PASSWORD='repl', MASTER_AUTO_POSITION=0;从库启动 slave 后,在主库查看 slave 列表,判断是否配置成功

# 半同步复制
MySQL 默认的复制是异步的
主库不关心从库是否已经接收并同步,就会直接返回结果给客户端
如果此时强行将从库提升为主,可能导致新主上的数据不完整
MySQL5.5 开启,以插件形式支持半同步复制
半同步复制介于异步和全同步之间,目的是保证至少一台从库的数据完整性
主库写入 binlog -> 主库提交事务 -> 等待从库写入 relaylog -> 返回结果在等待从库的过程中,客户端能在主库看到这个事务
如果主库宕机,可能产生重复提交,导致主从数据不一致
MySQL5.7 引入了新的半同步复制方案:Loss-Less半同步复制
提供参数来设置主库提交的时机
SET rpl_semi_sync_master_wait_point = AFTER_SYNCAFTER_COMMIT 是先提交事务再等待从库同步,AFTER_SYNC 是等待从库返回确认后,再提交事务
AFTER_SYNC 流程:
主库写入 binlog -> 等待从库写入 relaylog -> 主库提交事务 -> 返回结果MySQL 推荐使用 AFTER_SYNC 模式